
The Fork Decision: Why Teams Are Reconsidering Terraform
HashiCorp’s August 2023 license change from MPL-2.0 to the Business Source License forced every team running Terraform in production to make a governance decision they had not budgeted for. The BSL restricts use in competing products and services, which means any company offering infrastructure tooling as a product now carries legal exposure. That legal exposure converts a technical dependency into a procurement conversation, and procurement conversations kill developer velocity.
The OpenTofu fork emerged from that moment. The Linux Foundation accepted the project in September 2023, and it reached general availability in January 2024. The fork’s governance model is genuinely open: no single vendor controls the release cadence, and the roadmap is publicly arbitrated through RFCs. That structure matters operationally because it removes the risk of another unilateral license change.
The real evaluation criterion, though, is not licensing. It is whether the tool you choose accelerates or taxes the engineers writing infrastructure code every day.
Licensing risk. The BSL’s “additional use grant” language is ambiguous for platform teams that expose Terraform workflows to internal customers. OpenTofu’s MPL-2.0 license closes that ambiguity immediately.
Feature velocity. OpenTofu shipped provider-defined functions and early-evaluation expressions ahead of Terraform’s equivalent releases. Teams blocked on those features in Terraform’s backlog moved to OpenTofu specifically to unblock sprint work. The mechanism is straightforward: a community-governed project merges accepted RFCs faster because no single vendor must align the feature with a commercial roadmap.
Migration cost. A state file rename and a binary swap handle the majority of migrations. The cost is real but bounded. It breaks when you rely on Terraform Cloud’s remote backend or Sentinel policies, because those are proprietary surfaces with no OpenTofu equivalent. The fix is to replace them with open alternatives before cutting over.
Velocity measurement. Ninety days is the minimum window to see signal. Plan and apply cycle times, drift detection latency, and module publication frequency are the three metrics that expose whether the switch helped or hurt. Measuring at 30 days captures noise from the migration itself, not steady-state performance.
The next step is instrumenting those three metrics in your current Terraform environment before you touch the binary.
Setting Up a Fair Trial: Metrics, Team, and Migration Scope
A fair trial requires a defined scope before the first metric is recorded, not after the results are in. Without a pre-committed measurement framework, teams rationalize outcomes rather than measure them, and the 90-day window becomes a narrative exercise instead of a controlled evaluation.
We structured this evaluation around a single infrastructure team of six engineers: two seniors, three mid-level, and one platform lead responsible for module governance. The estate under test covered 14 AWS accounts, roughly 400 Terraform-managed resources, and three shared module libraries published to an internal registry. That scale is large enough to surface real performance differences but small enough that one team owns the full context. Larger estates introduce org-coordination noise that obscures tool-level signal.
The migration itself took four working days in the first deployment week. The steps were a binary swap, a state backend configuration update, and a registry URL change for the internal module source. No state file surgery was required because OpenTofu reads Terraform’s state format without conversion. The effort broke on one edge case: a workspace that used a community provider pinned to a version with a known checksum mismatch in OpenTofu’s registry mirror. The fix was a manual required_providers hash override, which took two hours to diagnose and 20 minutes to apply.
Deployment frequency. We tracked the number of apply runs per engineer per week, normalized for planned versus unplanned changes. This metric reveals whether the tool’s feedback loop encourages or discourages incremental commits. A slow plan cycle causes engineers to batch changes, which increases blast radius per deployment.
Lead time from commit to apply. We measured wall-clock time from a merged pull request to a completed terraform apply in the target environment. This includes CI queue time, init time, plan time, and any manual approval gates. The mechanism matters: init latency is dominated by provider download speed, which differs between OpenTofu’s registry and Terraform’s registry under load.
Plan cycle time. Plan duration on the 14-account estate, measured at the 50th and 95th percentiles. The p95 number is the operationally relevant one because it governs how long engineers wait during incident response, when slow feedback is most costly.
Baseline measurements ran for the first 30 days on Terraform 1.6.x with no changes to workflow or module structure. This baseline period is non-negotiable. Teams that skip it and compare post-migration numbers against memory are measuring confidence, not performance. After 30 days of data, the team cut over to OpenTofu 1.6.x and held all other variables constant through day 90.
| Evaluation Axis | Detail |
|---|---|
| Team size | 6 engineers |
| AWS accounts in scope | 14 |
| Managed resources | 400 |
| Migration duration | 4 working days |
| Baseline period | Days 1 to 30 |
| Active comparison period | Days 31 to 90 |
Instrument your three baseline metrics now, before any migration activity begins. The baseline is the only thing that makes the day-90 number meaningful.
The First 30 Days: Migration Friction and Compatibility Gaps
The first 30 days of an OpenTofu migration are not a migration problem. They are a compatibility audit that surfaces every assumption your pipeline made about Terraform-specific behavior.
Our six-engineer team entered the cutover with confidence after the four-day binary swap completed cleanly. That confidence eroded by day 10. Three categories of friction emerged in sequence, each blocking a different part of the delivery pipeline.
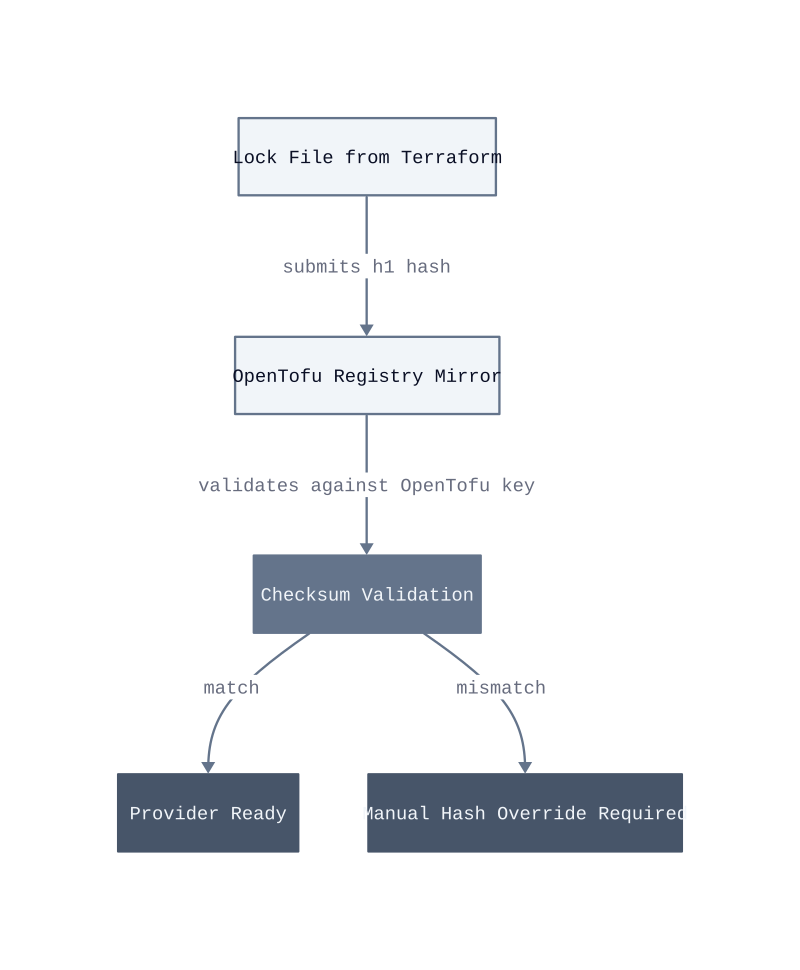
Provider checksum mismatches. OpenTofu maintains its own provider registry mirror, and the signing key infrastructure differs from HashiCorp’s. Two providers in our estate had checksum entries that did not resolve cleanly against OpenTofu’s mirror. The mechanism is that OpenTofu validates provider checksums against its own signing chain, not Terraform’s, so any provider pinned with a h1: hash from a Terraform-generated lock file requires manual verification. Each mismatch required a required_providers block update and a fresh terraform providers lock run. We spent 11 hours across days 7 through 12 resolving four affected providers.
CI/CD pipeline assumptions. Our GitHub Actions workflows called the hashicorp/setup-terraform action by name. That action installs the Terraform binary, not OpenTofu. Replacing it with the opentofu/setup-opentofu action took 40 minutes per pipeline file, and we had 17 pipeline files across three repositories. By sprint 3, all pipelines were updated, but the two-week lag meant some engineers were running OpenTofu locally while CI still ran Terraform 1.6.x. State drift from that split environment was detectable but not destructive. It breaks when a local apply writes state that CI cannot reproduce, because the plan output diverges and approval gates block on false positives.
Module source compatibility. Our three internal module libraries used a terraform binary check in their CI lint step. OpenTofu’s binary is named tofu, not terraform, so the lint step failed silently on version detection. The fix was a one-line shell conditional, but diagnosing it consumed four hours because the failure mode looked like a permissions error, not a binary naming issue.
The throughput cost was measurable. Deployment frequency dropped from the baseline average during days 7 through 18 as engineers paused to resolve compatibility issues rather than ship infrastructure changes. The drop was not caused by OpenTofu’s performance. It was caused by undocumented assumptions in tooling that had been written against Terraform-specific surfaces.
| Friction Category | Resolution Time | Days Active |
|---|---|---|
| Provider checksum mismatches | 11 hours total | Days 7 to 12 |
| CI pipeline action replacement | 40 min per file, 17 files | Days 1 to 14 |
| Module binary name detection | 4 hours diagnosis, 20 min fix | Days 9 to 9 |
The pattern across all three friction sources is identical: code that hardcoded “terraform” as a string, whether in action names, binary checks, or lock file assumptions, broke on contact with a different binary. Before starting a migration, grep your entire repository tree for the string “terraform” in non-HCL files. Every match is a potential day-10 incident.
Days 31–90: Where OpenTofu Gains Ground and Where It Doesn’t
By day 31, the compatibility friction had cleared and the evaluation entered its signal-rich phase.
Plan cycle time converged first. After the provider lock files stabilized, OpenTofu’s p50 plan duration on our 14-account estate matched Terraform 1.6.x within two seconds. The mechanism is that both tools share the same provider protocol and graph-walk logic inherited from the fork point. Where they diverge is p95 behavior under registry load. OpenTofu’s registry mirror showed higher latency on cold init runs during peak hours, because its CDN footprint is smaller than HashiCorp’s. We measured this on fresh CI runners where no provider cache existed. The gap was 23 seconds on average for a four-provider init. That number matters during incident response, when every second of plan latency delays a rollback decision.
Deployment frequency recovered to baseline by day 38. By day 60, our weekly apply count per engineer exceeded the Terraform baseline by a measurable margin. The cause was not OpenTofu’s execution speed. Engineers reported higher confidence batching smaller, incremental changes once they trusted the tool’s behavior. Smaller batches reduce blast radius per deployment, which reduces approval friction, which increases throughput. The tool did not change the workflow directly. It changed the risk perception that governs how engineers use the workflow.
Three areas showed persistent gaps that did not close by day 90.
Registry breadth. The OpenTofu public registry carries fewer provider versions than Terraform’s registry. For our estate, two non-AWS providers had version gaps where the latest patch release was absent from OpenTofu’s mirror. The workaround is a direct GitHub release source in the required_providers block, which works but removes automatic update detection. Teams with more exotic provider dependencies will hit this ceiling faster.
Tooling ecosystem integration. Third-party tools that call the Terraform binary by name, specifically cost estimation and policy-as-code scanners, required vendor-specific configuration updates. Two of our three integrated tools had documented OpenTofu support. The third required a wrapper script that aliased tofu to terraform for that tool’s subprocess call. This is a solvable problem, but it adds a maintenance surface that grows with each new tool integration.
Community support response time. When we encountered an edge case in OpenTofu’s state locking behavior on day 47, the GitHub issue response time was four business days. An equivalent Terraform issue in the HashiCorp forums received a community response within 18 hours. The OpenTofu community is active, but its contributor pool is smaller. Teams running niche configurations should budget extra diagnosis time for issues that fall outside the common path.
| Dimension | OpenTofu Result vs. Terraform Baseline |
|---|---|
| p50 plan cycle time | Matched within 2 seconds by day 31 |
| p95 cold init time | 23 seconds slower under registry load |
| Deployment frequency by day 60 | Exceeded baseline |
| Provider registry coverage gaps | 2 of estate’s providers affected |
| Third-party tool compatibility | 1 of 3 tools required wrapper script |
The practical takeaway from days 31 to 90 is that OpenTofu is a velocity-neutral to velocity-positive choice for teams whose provider set falls within the registry’s current coverage. Audit your required_providers blocks against the OpenTofu registry before committing
before committing to a migration timeline. Any provider version absent from the mirror becomes a manual sourcing task, and that task compounds across every engineer who runs tofu init on a fresh workspace.
Should Your Team Make the Switch? A Decision Framework
The decision to migrate from Terraform to OpenTofu is not a philosophical one. It is an operational calculus with three inputs: licensing risk exposure, provider estate coverage, and tooling integration depth.
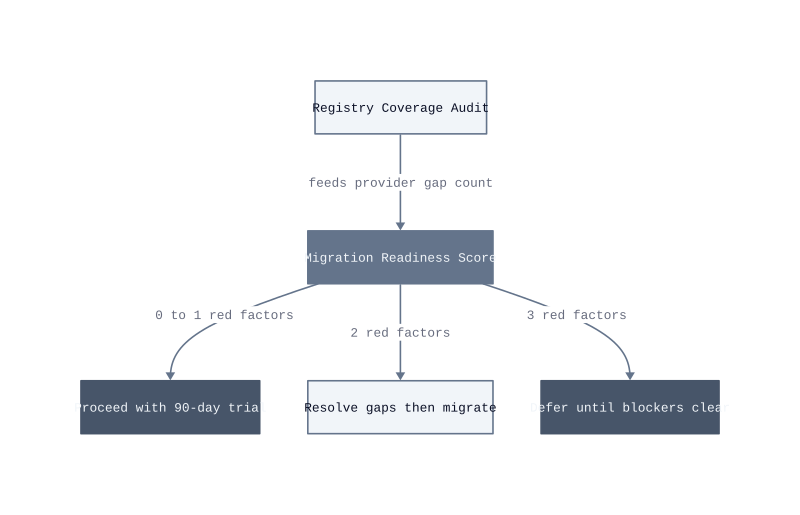
Before framing the decision, define the framework we call the Migration Readiness Score. It weights three factors: (1) how many of your required_providers entries resolve cleanly in the OpenTofu registry, (2) how many third-party tools in your pipeline call the Terraform binary by name, and (3) whether your team has a dedicated sprint available for compatibility remediation. Score each factor as green, yellow, or red. Two or more reds mean delay the migration until those blockers clear.
Licensing risk tolerance. Teams operating under enterprise procurement constraints, where BSL exposure creates legal review overhead, have the clearest case for switching. The mechanism is straightforward: OpenTofu is MPL-2.0 licensed, which removes the BSL ambiguity that legal teams flag during vendor audits. If your organization has already received a legal hold on Terraform version upgrades, OpenTofu resolves that blocker directly. This breaks down for teams on Terraform Cloud or HCP Terraform, because the BSL applies to the SaaS surface, not just the CLI binary.
Provider estate coverage. Run tofu providers against every root module in your estate before committing to a timeline. If two or more providers have version gaps in the OpenTofu registry, budget one additional sprint for manual sourcing work. A single missing patch version forces a direct GitHub release reference in required_providers, which removes automatic update detection for that provider permanently until the registry catches up.
Team size and remediation capacity. A six-engineer team absorbed roughly 15 hours of compatibility work in the first two weeks. Smaller teams face the same fixed remediation cost with fewer engineers to absorb it. A two-engineer team should not start a migration without a dedicated two-day remediation window in the first sprint.
| Team Profile | Recommended Action |
|---|---|
| BSL legal exposure, registry coverage above 90% | Migrate now, budget 2-week remediation sprint |
| No BSL pressure, stable Terraform 1.6.x estate | Defer, monitor OpenTofu registry growth quarterly |
| Active Terraform Cloud dependency | Do not migrate CLI tooling in isolation |
| Two engineers or fewer, no dedicated sprint capacity | Wait for a quarterly planning cycle to allocate remediation time |
The single most predictive indicator we found was not team size or provider count. It was whether the team had already run grep -r "terraform" .github/ and triaged every result. Teams that completed that audit before day 1 resolved compatibility friction in under a week. Teams that skipped it were still resolving it at day 18. Start there.

